

This document outlines a comprehensive approach to designing and configuring AWS auto-scaling groups, load balancers, and caching mechanisms. Our goal is to ensure optimal performance and scalability during unpredictable AWS Traffic Spikes. Additionally, we will explore best practices and practical examples. Furthermore, modern solutions will be discussed to address common challenges cloud architects and engineers face.
Content:
- Understanding AWS Traffic Spikes
- Optimizing Auto-Scaling Groups for AWS Traffic Spikes:
- Load Balancing for AWS Traffic Spikes:
- Caching: Easing Database Load During AWS Traffic Spikes
- Implementing a Disaster Recovery Plan
- Monitoring and Optimization for AWS Traffic Spikes
- Example: A Real-World Case Study
- Advanced Techniques for Improved Scalability
- Cost Optimization Strategies for AWS Traffic Spikes
- AWS Traffic Spikes: Scalable Solutions
- Deployment Strategies for AWS Traffic Spikes:
- AWS Traffic Spikes: CI/CD
- Best Practices Summary for AWS Traffic Spikes:
- AWS Traffic Spikes: Challenges & Considerations
- Conclusion
- FAQs:
- How can I predict and prepare for potential traffic spikes on AWS?
- What are the key components to focus on when designing for AWS traffic spikes?
- How do I set up effective monitoring and alerting systems for AWS traffic spikes?
- What are the best strategies for auto-scaling to handle sudden traffic increases?
Understanding AWS Traffic Spikes
AWS traffic spikes are sudden increases in network traffic to your AWS applications. These can be caused by various factors, including below listed:
- Promotional campaigns,
- Seasonal events,
- Viral content, and
- Cyberattacks.
Consequently, such spikes can overwhelm your infrastructure, leading to slow performance, downtime, and even application crashes. As a result, this can negatively impact your user experience and business operations.
Optimizing Auto-Scaling Groups for AWS Traffic Spikes:
Auto-scaling groups (ASGs) are a cornerstone of AWS’s scalability solution. They automatically adjust the number of instances in your application’s infrastructure based on predefined metrics. Consequently, this ensures you always have the right computing power to handle the current workload.
- First, configure ASGs to monitor metrics like CPU utilization, memory usage, or network traffic.
- Next, set scaling policies to add or remove instances based on pre-defined thresholds automatically.
- Finally, leverage the “cooldown” period to prevent over-provisioning or unnecessary scaling events.
Load Balancing for AWS Traffic Spikes:
Load balancers are essential for distributing incoming traffic across multiple instances in your ASG. They go about as a critical issue of contact. However, this ensures each instance receives a fair share of requests. Consequently, this prevents any single instance from becoming overloaded.
- To achieve this, utilize AWS Elastic Load Balancing (ELB) to distribute traffic across your ASG instances. ELB offers various types, including Application Load Balancers (ALB) for HTTP/HTTPS traffic. Additionally, it includes Network Load Balancers (NLB) for TCP/UDP traffic.
- Moreover, configure health checks to monitor the health of your instances. Therefore, this allows you to route traffic away from unhealthy cases automatically.
- Finally, implement sticky sessions if your application requires session affinity. Consequently, this ensures a user’s requests are consistently routed to the same instance.
Caching: Easing Database Load During AWS Traffic Spikes
Caching is a robust method for improving application performance levels. It stores frequently accessed data in memory or local storage. As a result, this reduces the need to access the database for every request. Consequently, it leads to faster response times and reduced database load.
- First, implement caching at different levels. In addition, this includes web server caching, such as using Nginx or Apache. Additionally, use application caching, such as Memcached or Redis. Moreover, database caching can be done using Amazon ElastiCache for Redis or Memcached. Moreover, database caching can be done using Amazon ElastiCache for Redis or Memcached.
- Furthermore, caching strategies like content delivery networks (CDNs) should be used. CDNs deliver static content, such as images and CSS files, from edge locations closer to users.
- Finally, implement cache invalidation techniques. Consequently, this ensures that cached data is updated when underlying data changes.
Implementing a Disaster Recovery Plan
It’s essential to have a disaster recovery plan in place to handle unexpected events, including traffic spikes that can cause outages.
Transitioning to AWS provides various services to support disaster recovery:
- Amazon S3: Amazon S3 is utilized to store data backups. It offers high durability and availability, ensuring your data is safe.
- Amazon EBS: Additionally, utilize Amazon EBS snapshots to back up your EC2 instance volumes. Therefore, this allows for quick restoration of your instances.
- Amazon RDS: Moreover, Amazon RDS can manage database backups automatically. Consequently, this ensures your database can be restored at any point in time.
Regularly back up your data and applications to ensure you can recover quickly in case of a catastrophic event. By leveraging these AWS services, you can enhance your disaster recovery capabilities and maintain business continuity.
Monitoring and Optimization for AWS Traffic Spikes
Constant monitoring ensures that your auto-scaling groups, load balancers, and caching mechanisms function optimally. Monitor key metrics like:
- Auto Scaling Group(ASG) instance count and scaling events
- ELB health checks and request distribution
- Cache hit rates and cache eviction rates
By analyzing these metrics, you can make necessary adjustments to scaling policies, cache configurations, and other settings to fine-tune your system. Therefore, this proactive approach ensures optimal performance and delivers a seamless user experience.
Example: A Real-World Case Study
Scaling Your Online Shopping Platform for Peak Demand
To handle peak demand during holiday sales and prevent performance degradation, implement the following solution:
First, configure an Auto-Scaling Group (ASG) to automatically scale the number of EC2 instances running your application based on CPU utilization metrics. Therefore, this ensures your application can handle increased traffic by adding more instances.
Next, use an Application Load Balancer (ALB) to distribute traffic across the instances in your ASG. Consequently, this ensures no instance becomes overloaded, maintaining a smooth user experience.
Additionally, a caching solution like Amazon ElastiCache for Redis should be implemented. This stores frequently accessed product data in memory, reducing database load and speeding up response times.
By following these steps, your platform will be better equipped to handle significant surges in traffic without compromising performance.
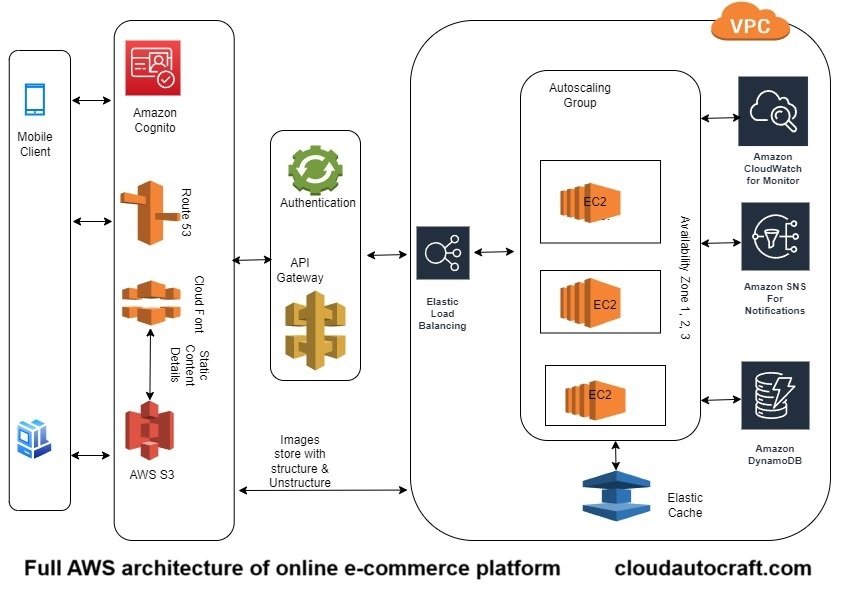
Advanced Techniques for Improved Scalability
While auto-scaling, load balancing, and caching are essential for handling dynamic traffic, additional techniques can further enhance your application’s scalability:
Embracing Serverless Computing: Leveraging AWS Lambda enables seamless code execution without the hassle of managing servers. Lambda dynamically scales in response to demand, reducing operational overhead and enhancing cost efficiency.
Adopting Microservices Architecture: Breaking down your application into more minor, independent services connected through APIs fosters agility. This approach empowers you to scale individual services autonomously, ensuring heightened responsiveness to fluctuations in traffic.
Harnessing Containerization: Employing containerization technologies like Docker streamlines application packaging and deployment. However, these lightweight, portable containers facilitate seamless scaling across diverse environments, spanning on-premises setups to cloud infrastructure.
By integrating these methodologies, you can unlock superior scalability, flexibility, and efficiency for your online shopping platform.
Cost Optimization Strategies for AWS Traffic Spikes
Scalability often comes with cost considerations. To optimize cost without compromising performance, consider:
| Leverage Auto Scaling: Automatically adjust the number of EC2 instances based on your traffic demand to ensure you only pay for what you use. | Utilize Spot Instances: Take advantage of AWS Spot Instances for flexible, non-critical workloads to save costs during traffic spikes. |
| Employ AWS Savings Plans: Commit to consistent usage to reduce costs for steady-state traffic, allowing us to manage spikes cost-effectively. | Moreover, elastic load balancing is used, which distributes incoming application traffic across multiple targets to optimize resource use and minimize costs during high-traffic periods. |
| Implement CloudFront CDN: Cache static and dynamic content closer to your end users with Amazon CloudFront to reduce latency and lower data transfer costs. | In addition, Optimize Storage Costs: Use S3 Intelligent Tiering for automatic cost savings by moving data between two access tiers when your access patterns change. |
| Enable RDS Aurora Serverless: Automatically adjust database capacity based on your application needs to handle unpredictable workloads cost-efficiently. | Monitor and Analyze with Cost Management Tools: Utilize AWS Cost Explorer and AWS Budgets to gain insights into your spending patterns and optimize resource usage in real-time. |
| Right-Size Instances: Monitor and adjust instance types and sizes to match your current and projected demand, ensuring optimal performance and cost efficiency. | Leverage Reserved Instances: Buy Reserved Instances for your predictable workloads to get substantial discounts while balancing with on-demand and spot instances for sudden traffic increases. |
| Optimize Data Transfer Costs: Use AWS Direct Connect or VPC Peering to reduce your data transfer costs between AWS services and on-premises environments. | Finally, adopt serverless architectures: Use AWS Lambda to handle your traffic surges without provisioning servers, ensuring you only pay for the computing time consumed. |

By implementing these strategies, you can achieve scalability while optimizing costs for your infrastructure on AWS.
AWS Traffic Spikes: Scalable Solutions
Scalability and security are equally important. As you implement auto-scaling, load balancing, and caching, prioritize security best practices:
| Network Segmentation: | By isolating your application’s components into different security groups, you can restrict access and minimize the impact of security breaches. Overall, this segmentation enhances the entire security posture of your system. |
| Secure Configuration: | Transitioning to Secure Configuration involves enforcing robust security settings on your ASGs, load balancers, and caching services. Implementing security policies, access control lists, and encryption mechanisms helps safeguard your data and resources from unauthorized access and potential cyber threats. |
| Monitoring and Logging: | Continuous monitoring of your application’s security posture is essential. Ensure that security logs are captured and analyzed regularly to identify potential vulnerabilities promptly. This proactive approach enables you to respond effectively to security threats, maintaining the integrity and security of your system. |
Deployment Strategies for AWS Traffic Spikes:
Deploying your application to AWS in a way that supports scalability and resilience is crucial. Consider these approaches:
| Blue-Green Deployment: | Deploy a new application version to separate instances. Route traffic should be migrated gradually to minimize downtime and allow quick rollback if issues arise. |
| Canary Deployment: | Release a new version to a small subset of users (canary group). Monitor its performance before rolling it out to the entire user base. Consequently, this helps identify and fix potential issues early on. |
| Automated Rollouts: | Automate the deployment process using AWS CodePipeline and CodeDeploy tools. Thus, this ensures consistency and reduces the risk of human error during deployments. |
In this video, learn about more Deployment Strategies :
AWS Traffic Spikes: CI/CD
Implementing CI/CD practices streamlines your application development and deployment processes. As a result, this makes it easier to adapt to changing traffic patterns and deploy updates quickly.
CI/CD involves:
Automated Testing: Regularly run tests to ensure new code changes do not introduce regressions. Therefore, this maintains your application’s stability and scalability.
Continuous Integration: Integrate code changes into a shared repository frequently. However, this allows for early detection of conflicts and facilitates developer collaboration.
Continuous Deployment: Automatically deploy new code changes to production environments once they pass automated tests. Hence, this accelerates the delivery of new features and bug fixes, enhancing your application’s agility and responsiveness to user needs.
Best Practices Summary for AWS Traffic Spikes:
Monitoring and Alerting: To ensure proactive management of your system, implement robust monitoring and alerting systems. Consequently, this enables you to identify and respond to traffic spikes swiftly. Utilize AWS CloudWatch and set up alarms for critical metrics to stay ahead of potential issues.
Auto Scaling: Transitioning to Auto Scaling, leverage AWS Auto Scaling to adjust your infrastructure capacity based on real-time demand dynamically. It’s crucial to have sufficient scaling policies to manage workload fluctuations effectively.
Elastic Load Balancing: ELB will distribute incoming traffic evenly across multiple instances. Hence, this mitigates the risk of bottlenecks and maintains consistent performance levels even during peak usage periods.
Caching: Implementing caching strategies is vital for optimizing backend server performance. By storing frequently accessed data, caching reduces the load on servers. Explore AWS CloudFront and Amazon Elastic Cache to enhance caching capabilities and improve overall system efficiency.
AWS Traffic Spikes: Challenges & Considerations
While these techniques offer significant advantages for handling dynamic traffic, there are challenges to consider:
| Cost Management: | Scaling resources can be expensive, especially during peak traffic. Monitor and optimize your scaling policies and resource utilization to control costs effectively. |
| Performance Bottlenecks: | Despite employing auto-scaling, load balancing, and caching, performance bottlenecks might still arise. Analyze your application’s performance and identify areas for optimization to ensure smooth operation under varying loads. |
| Complexity: | Managing a complex system with multiple moving parts can be challenging. Implement monitoring and automation tools to simplify operations and ensure reliability throughout your infrastructure. |
Conclusion
You can create an application that gracefully handles unpredictable traffic spikes by designing and configuring auto-scaling groups. Additionally, integrating load balancers ensures optimal distribution of traffic. Moreover, implementing caching mechanisms further enhances performance and scalability.
Furthermore, this document has presented best practices, practical examples, and modern solutions to address common challenges cloud architects and engineers face. Remember to continuously monitor your system, optimize its performance, and embrace advanced techniques to build a truly resilient and scalable architecture on AWS.
Click here To learn more about DevOps-Security 2024 && Cyber Security 2024
FAQs:
How can I predict and prepare for potential traffic spikes on AWS?
Answer: Predicting and preparing for potential traffic spikes on AWS involves leveraging historical data analysis and forecasting techniques. We can proactively adjust resources based on demand by utilizing AWS services like CloudWatch to monitor key metrics and set up alarms for unusual spikes. Implementing auto-scaling groups ensures readiness for sudden surges in traffic.
What are the key components to focus on when designing for AWS traffic spikes?
Answer: Designing for AWS traffic spikes requires focusing on critical components such as scalability, fault tolerance, and performance optimization. Utilizing distributed architectures, microservices, and caching mechanisms handles increased loads. Content delivery networks (CDNs) and load balancers evenly distribute traffic, minimizing latency.
How do I set up effective monitoring and alerting systems for AWS traffic spikes?
Answer: Setting up effective monitoring and alerting systems for AWS traffic spikes involves configuring AWS CloudWatch to monitor relevant metrics such as CPU utilization, network traffic, and request rates. Creating alarms triggers notifications when thresholds are exceeded. Integrating third-party monitoring tools provides comprehensive visibility into system performance.
What are the best strategies for auto-scaling to handle sudden traffic increases?
Answer: Implementing proactive auto-scaling strategies handles sudden traffic increases. Defining scaling policies based on metrics like CPU utilization, request latency, or queue length is crucial. Utilizing predictive scaling anticipates traffic patterns, scaling resources accordingly. Regularly testing and optimizing auto-scaling configurations ensures responsiveness and efficiency.
Originally posted 2024-06-22 14:55:53.