

For example, your mission-critical applications on AWS need to stay highly available and ensure business continuity during a disaster. How would you design and implement a High Availability & Disaster Recovery architecture with built-in redundancy, failover mechanisms, and automated processes?
Designing a robust, highly available, and disaster-proof architecture is vital for mission-critical applications on AWS. This guide will walk you through fundamental principles and strategies to ensure business continuity and uninterrupted service, even during unexpected outages or disasters.
Content:
- Principles & Failover for High Availability & Disaster Recovery
- Automated Failover and Disaster Recovery
- Leveraging AWS Availability Zones and Regions
- High Availability & Disaster Recovery: Backup Plan
- Failover and Disaster Recovery Testing
- High Availability & Disaster Recovery: Cost Optimization
- High Availability and Disaster Recovery: Incident Response
- High Availability and Disaster Recovery: Automation
- Monitoring High Availability and Disaster Recovery
- Disaster Recovery Strategies
- Conclusion: High Availability & Disaster Recovery
- FAQs:
- What are the considerations for network design in a high availability and disaster recovery setup on AWS?
- How do you handle data consistency and replication across multiple regions?
- What are the security considerations for High Availability & Disaster Recovery setups on AWS?
- How can you optimize costs while maintaining High Availability & Disaster Recovery capabilities?
Principles & Failover for High Availability & Disaster Recovery
Principles of High Availability:
If you want your system to be reliable, you must build it with redundancy at every level. So, That means having backup computing resources, storage, networking, and other vital components. If one part fails, the rest can keep things running smoothly.
Furthermore, it’s also essential to make your application stateless and scalable. This lets you easily add or remove resources as needed to handle changes in traffic or resource use. Using AWS services like Auto Scaling, Elastic Load Balancing, and multi-AZ deployments can help you do this.
Failover and Disaster Recovery:
When disasters or outages occur, you need a solid plan to get your application back up and running quickly. However, This means seamlessly switching to a different AWS Region if necessary so your users can still access your services.
Moreover, replicating your data across regions is crucial. A global content delivery network (CDN) can improve your disaster recovery strategy. Furthermore, automating the failover process is a must. AWS offers services like Amazon S3, Amazon RDS, and AWS Lambda that can help you set all this up.
Automated Failover and Disaster Recovery
When disaster strikes, you need your systems to bounce back quickly. The key is automating your disaster recovery procedures as much as possible. You can use AWS services like Amazon Route 53, AWS Lambda, and Amazon CloudFormation to create automated failover and recovery workflows. These workflows can be triggered when an outage happens.
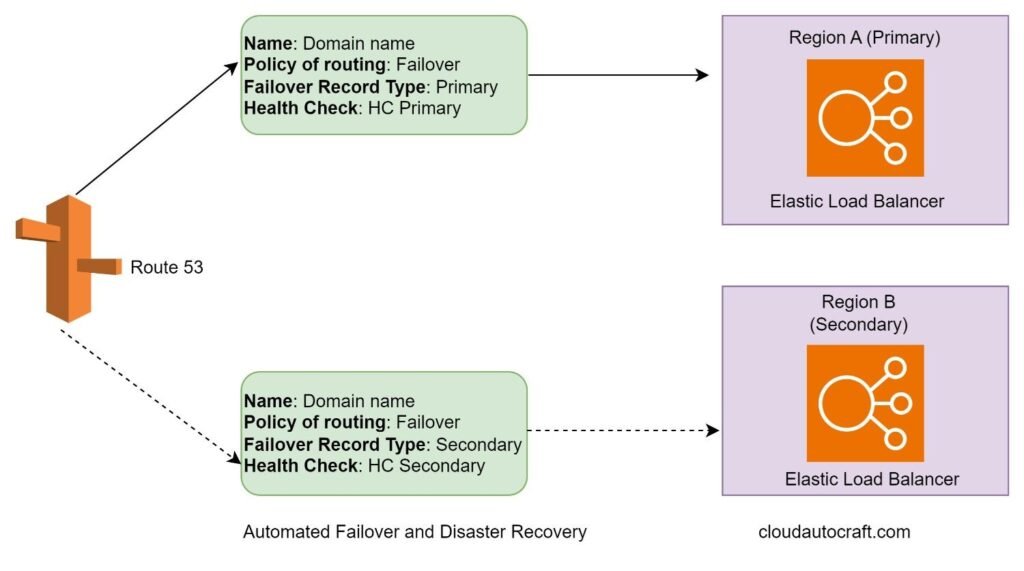
You can use AWS services like Amazon Route 53, AWS Lambda, and Amazon CloudFormation to create automated failover and recovery workflows. These workflows can be triggered when an outage happens.
Moreover, these automated processes should handle all the critical tasks. Moreover, this includes changing DNS routing, failing over databases, and deploying backup infrastructure in a secondary AWS Region. Automating these steps can dramatically reduce the time and effort needed to recover.
Leveraging AWS Availability Zones and Regions
| Availability Zones | AWS Availability Zones (AZs) are separate data centres within a single AWS Region. By spreading your application across multiple AZs, you can ensure a failure in one AZ doesn’t take down your whole service. |
| AWS Regions | On the other hand, AWS Regions are physically isolated locations, often far apart. Consequently, This protects against large-scale disasters, like natural calamities or regional outages. Architecting your app to failover across Regions can pay off in a crisis. |
| Multi-Region Architectures | You can deploy your application in a multi-region setup for even more redundancy, with active-active or active-passive configurations. Hence, This ensures your users can access your services, no matter what happens to an entire AWS Region. |
The bottom line is that leveraging AWS’s global infrastructure is critical to building a resilient, highly available system. With the right mix of Availability Zones, Regions, and multi-region architectures, you can keep your business running smoothly, no matter what comes your way.
High Availability & Disaster Recovery: Backup Plan
| Backup Data: First things first, you need to back up your critical data regularly. AWS S3 and other durable storage solutions are excellent choices for this purpose for back up. And make sure those backups are stored in a different AWS Region from your primary application. |
| Database Replication Next, implement cross-region replication for your databases. To ensure your data is consistently available in multiple regions, you can use services like Amazon RDS or Amazon DynamoDB Global Tables. |
| Object Storage Replication Don’t stop there—leverage Amazon S3 cross-region replication to automatically replicate your object storage data to a secondary Region. In addition, This provides an extra layer of data redundancy. |
| Serverless Replication Consider using the built-in cross-region replication capabilities for your serverless components, like AWS Lambda functions and Amazon DynamoDB tables. Finally, This helps maintain data consistency and availability across Regions. |
Check this below video to learn more about How to Design Highly Available Architecture.
Failover and Disaster Recovery Testing
When it comes to disaster recovery, you can’t just set it and forget it. Regular testing is essential to make sure your system can handle the unexpected. Conduct periodic failover drills, simulating different failure scenarios. This allows you to validate your processes and identify areas for improvement.
To make testing easier, AWS services like CloudFormation, Step Functions, and Route 53 can be used to automate the process. In the same way, you can run comprehensive tests and analyse the results more efficiently.
By continuously testing and refining your high availability and disaster recovery strategies, you can ensure your mission-critical applications remain resilient and accessible to your users, no matter what happens.
High Availability & Disaster Recovery: Cost Optimization
Designing a highly available and disaster-resilient architecture can be expensive. You need to maintain redundant resources and infrastructure across multiple Regions. However, it’s also crucial to consider the potential business impact of an outage or disaster.
The key is to find the right balance between cost and resilience. Therefore, Here are some tips to help you optimize your high availability and disaster recovery solutions:
| Leverage Managed Services: First, leverage fully managed AWS services, like Amazon RDS, Amazon DynamoDB, and AWS Lambda. This offloads infrastructure management tasks and reduces the overall cost. |
| Optimize Resource Utilization: Next, implement AWS cost-effective scaling and resource utilization strategies. Things like Auto Scaling, Spot Instances, and Serverless computing can minimize the cost of your redundant infrastructure. |
| Automate Failover Triggers: Finally, automate your failover and disaster recovery processes as much as possible. This will reduce the need for manual intervention and reduce the operational costs associated with incident response. |
High Availability and Disaster Recovery: Incident Response
Even with the best high availability and disaster recovery plan, unexpected things can still happen. That’s why You have to implement a solid incident response plan, which is very important.
When issues arise, you need to be able to identify, respond to, and fix them quickly. Monitor your system’s performance very closely. You should track key metrics and analyze incident logs. Therefore, it will help you to spot areas that need improvement.
Also, use AWS tools like CloudWatch, CloudTrail, and X-Ray. These give you a clear view of your application’s behaviour. This insight can help you enhance your high availability and disaster recovery strategies.
High Availability and Disaster Recovery: Automation
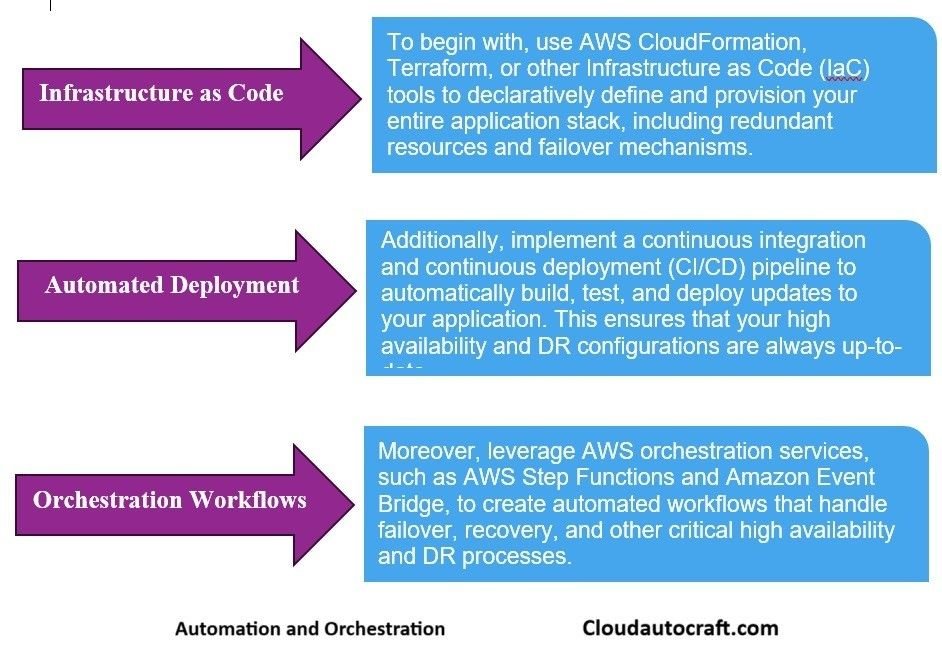
Monitoring High Availability and Disaster Recovery
| Comprehensive Monitoring To monitor your system closely, set up a robust monitoring solution like Amazon CloudWatch. This lets you track key metrics, logs, and events across your whole application—from the infrastructure to the network to the app itself. | Distributed Tracing Use AWS X-Ray or other tracing tools to get end-to-end visibility into how your application is performing. Consequently, This helps you quickly find and fix any issues that could impact availability. |
| Anomaly Detection Take it a step further with machine learning-powered anomaly detection from CloudWatch. Therefore, This can spot unusual trends that might signal potential problems before they happen. | Dashboards and Reporting Pull everything together with custom dashboards and reports. Hence, This gives your team a comprehensive view of your high availability and disaster recovery metrics. Now, you can make data-driven decisions and keep improving. |
Disaster Recovery Strategies
- Backup and Restore :
Start by setting up a backup and restore plan. Regularly back up your data and application components to another AWS Region. This way, if something goes wrong, you can quickly restore everything. - Warm Standby:
Next, keep a warm standby environment in a secondary AWS Region. Your application is constantly replicated and ready to go live if needed. - Active-Active:
Also, consider an active-active setup. In this setup, your application runs in multiple AWS Regions simultaneously. This approach ensures smooth failover and immediate disaster recovery.
Conclusion: High Availability & Disaster Recovery
Designing and building a highly available and disaster-resilient setup for critical apps on AWS takes a solid plan. So, You must combine redundancy, failover methods, automated processes, and constant monitoring. Consequently, AWS offers robust tools to help keep your applications running smoothly, even during unexpected outages or disasters. So, Use these tools to ensure your apps stay accessible and resilient. Furthermore, Remember that high availability and disaster recovery aren’t just one-time tasks. So, They need regular testing, tweaking, and improvement. By staying alert and addressing potential risks proactively, you can protect your critical apps and ensure your users get the reliable, uninterrupted service they expect.
Click here to Read more about Cloud-Security && Cyber Security
FAQs:
What are the considerations for network design in a high availability and disaster recovery setup on AWS?
Answer: In our high availability setup on AWS, we spread our deployment across multiple Availability Zones for redundancy. We use Elastic Load Balancing to distribute traffic efficiently. Similarly, Auto Scaling helps by adjusting resources based on demand. We have strong backup and restore processes to keep our data safe. AWS Global Accelerator and CDN boost performance. Additionally, we ensure strong security with AWS VPC and encryption to protect our data. Also, We monitor our network performance closely with proactive alerts, which help us minimize downtime and stay reliable.
How do you handle data consistency and replication across multiple regions?
Answer: To ensure data consistency, use Multi-AZ for RDS. For DynamoDB, go with quorum-based replication. Implement strong transaction management, too. Check for consistency regularly. Lastly, monitor and enforce with AWS CloudWatch and AWS Config.
What are the security considerations for High Availability & Disaster Recovery setups on AWS?
Answer: Encrypt data at rest with AWS KMS and in transit using TLS/SSL. also, Apply strict IAM policies and follow least-privilege principles. Moreover, Secure your network with VPCs, security groups, and ACLs. Therefore, Ensure compliance with GDPR and HIPAA. Finally, an incident response plan should be prepared, and AWS Security Hub and GuardDuty should be used for monitoring.
How can you optimize costs while maintaining High Availability & Disaster Recovery capabilities?
Answer: Adjust instance sizes regularly. Use Spot Instances for non-critical workloads and Reserved Instances for steady-state usage. Therefore, auto-scaling should be implemented, and S3 lifecycle policies should be set. Optimize cross-region data transfers with CloudFront. Monitor costs using AWS Cost Explorer and AWS Budgets.
Originally posted 2024-06-01 09:29:49.